"This is one reason that ASICs have significantly lower power than processors. They generally minimize the use of large centralized memories, and prefer local registers or recomputation. Further, these local registers provide direct communication in a pipelined stream-like fashion between compute entities and avoid the use of shared memories to pass values."
공유된 메모리가 에너지 소모를 크게 한다는 이야기입니다. ASIC이 전력소모가 적은 이유가 공유 메모리를 쓰기 보다는 재계산이나 통신(파이프라인에 직접)을 통해 전달하기 때문입니다.
Embedded Systems Design에서 기사를 본 거였는데, 발표자료를 찾아보니 같은 내용이 있기에 보니까 저자가 같네요. 2007년 기사입니다.
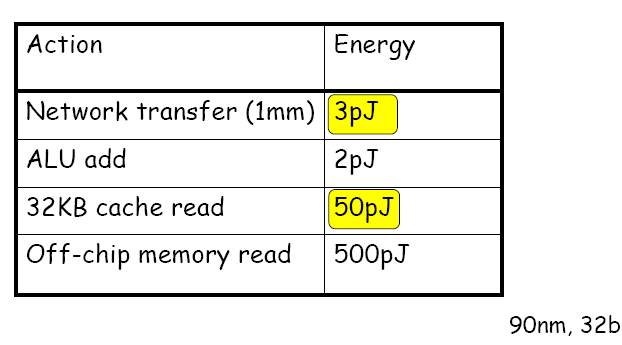
Communication Cheaper than Memory Access, Anant Agarwal
위의 표를 보면 차라리 네트웍으로 보내는 것이 캐시나 메모리를 통하는 것 보다 훨씬 적게 에너지가 소모됩니다. 되도록 공유 메모리를 적게 쓰는 것이 좋겠네요. 그리고 메모리 자체도 작게 (footprint)
그래서 말인데,
왜 ASIC으로 하면 전력소모가 적은데 그걸 embedded processor를 써서 만들면 에너지 소모가 클 수밖에 없을까요?
같은 일을 해도 OS 올라가고 메모리 붙이고 하면 에너지 소모가 크게 됩니다. 또 multicore라도 shared memory model은 어쩔수 없나봅니다. 에너지 소모가 ASIC보단 많게되겠네요
어쩌면 SW 패러다임이 바뀌어야할 것 같습니다. 멀티코어가 1K ,10K쯤 되면 코어들은 일종의 look-up table이 될 거라고 하던데 그럴 때는 메모리 공유보다는 네트웍 모델이나 stream 모델이 맞을 것 같습니다. 그런 이름이 있는지는 모르지만. streamC라는 게 있던데.. 좀 된 자료입니다. 2002년. http://graphics.stanford.edu/streamlang/ 구글에서 stream processor를 찾아보면 많이 나오는군요. 이건 어떻게 봐야되나
http://www.embedded.com/products/integratedcircuits/173400008?_requestid=405592 여길 나중에 좀 읽어봐야겠습니다.







 Presentation-A Hardware_Software Framework for supporting Tran..
Presentation-A Hardware_Software Framework for supporting Tran..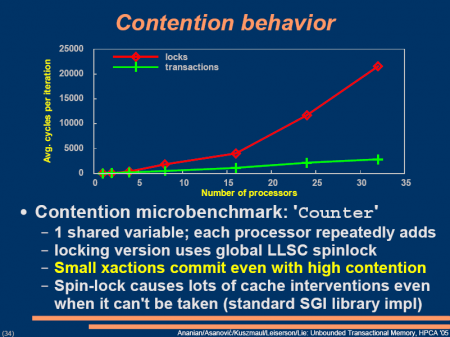
 I was senseless and ignorant; I was a brute beast before you.
Yet I am always with you; you hold me by my right hand.
You guide me with your counsel, and afterward you will take me into glory.
Whom have I in heaven but you?
I only have you in my life
I was senseless and ignorant; I was a brute beast before you.
Yet I am always with you; you hold me by my right hand.
You guide me with your counsel, and afterward you will take me into glory.
Whom have I in heaven but you?
I only have you in my life