Dual-Core Execution(DCE)이란 single thread 프로그램을 코어 두개로 실행해서 빠르게 하겠다는 것인데, 이번 논문은 여기에 중복되는 계산을 좀 줄여서 파워와 안정성을 개선하겠다는 것인 듯.
Compared to the original DCE, the optimized DCE has similar speedups (34 percent on average) over single-core processors while reducing the energy overhead from 93 percent to 31 percent.
역시 에너지는 싱글 코어 때보다 더 소모되긴 하는데, 속도 30% 증가에 에너지 30% 더 소모. linear하군요. 그게 진짜인지는 논문을 읽어봐야 할 듯.
rMPI: Message Passing on Multicore Processors with On-Chip Interconnect
With multicore processors becoming the standard architecture, programmers are faced with the challenge of developing applications that capitalize on multicore’s advantages. This paper presents rMPI, which leverages the on-chip networks of multicore processors to build a powerful abstraction with which many programmers are familiar: the MPI programming interface. To our knowledge, rMPI is the first MPI implementation for multicore processors that have on-chip networks. This study uses the MIT Raw processor as an experimentation and validation vehicle, although the findings presented are applicable to multicore processors with on-chip networks in general. ...
MPI를 사용한 CMP용 rMPI.
MPI가 오버헤드가 크긴 하다. Shared memory(pthread)를 쓰는 경우보다.
A program’s cache performance can be improved by changing the organization and layout of its data—even complex, pointer-based data structures. Previous techniques improved the cache performance of these structures by arranging distinct instances to increase reference locality. These techniques produced significant performance improvements, but worked best for small structures that could be packed into a cache block.
PinOS is an extension of the Pin dynamic instrumentation framework for whole-system instrumentation, i.e., to instrument both kernel and user-level code. It achieves this by interposing between the subject system and hardware using virtualization techniques. Specifically, PinOS is built on top of the Xen virtual machine monitor with Intel VT technology to allow instrumentation of unmodified OSes.
PinOS is based on software dynamic translation and hence can perform pervasive fine-grain instrumentation. By inheriting the powerful instrumentation API from Pin, plus introducing some new API for system-level instrumentation, PinOS can be used to write system-wide instrumentation tools for tasks like program analysis and architectural studies. As of today, PinOS can boot Linux on IA-32 in uniprocessor mode, and can instrument complex applications such as database and web servers.
멀티코어로 가는 대세 - 더이상 클럭을 올려서는 힘들고 여러개 코어로 나눠 일하는 concurrency 를 공략하는게 대세다 참고로 2003년 이후로는 거의 클럭이 올라가지 않고 있다. 클럭을 올려 속도를 빨리 하는 대신에 여러 코어에서 나눠 돌려서 전체적인 처리작업량을 늘리는 방법을 쓴다. 이렇게 하면 에너지(열)은 클럭주파수의 제곱에 비례하므로 낮은 클럭의 칩을 여러개 써서 높은 클럭 칩 하나로 일하는 것과 같은 성능을 낸다면 대체로 에너지를 더 적게 소모하고 열이 더 적게 나게 된다. 그러나 여러 코어에서 돌리려하면 일을 나누는 것, 그리고 나눠서 잘 돌아가게 관리해주는 게 필요하다.
예를 들어서 피자 집에서 배달을 시키는데 원래 한명이 배달하다가 손님이 많아져서 두명으로 늘렸다고 치자. 아무리 둘로 늘려도 효울이 두배로 늘려면 당연히 피자가 나오는 속도가 두배여야 한다. 그리고 혹, 오토바이나 피자 배달을 준비하기 위한 데크등이 공용된다면 공용되는 자원을 누가 먼저 사용하는지 규칙이 있어야 하고 한번에 한사람만 쓰도록 관리해줘야 한다.
원래 기존에 컴퓨터과학에서 많이 쓰던게 락(잠금)기법인데 잠가버려서 한번에 하나만 쓰게 보장된다. 그러나 혹시 락을 건 상태로 프로세스가 죽거나 잠들어버리면 다른 기다리는 프로세스들은 하염없이 기다리게 된다. 기타 여러 문제가 있는데 이걸 해결해보고자 transactional memory가 나왔었다. 최근에 멀티코어가 많이 나오면서 다시 재조명 받게 된 주제인데
컨셉은 일단 해본다. 그리고 잘 안되면 기다렸다 다시 한다. 이다.
그러니까 공유자원 A가 있다면 모든 각각의 프로세스에서 기본적으로 다른프로세스가 내가 자료 A를 처리하는 동안에 A를 바꾸지 않았다는 가정하에 일단 계산을 해본다. 프로세스1이 그랬다고 치고 그리고 A값을 아마 업데이트 할텐데 그 전에 혹시 다른 프로세스가 A를 바꿨다면 이 프로세스1은 바꿨다는 것을 인식하게 된다.(인식하는 방법은 이 논문에 나온 방법은 하드웨어적으로 Cache Coherency를 이용한다.) 이때 Abort가 발생한다. 그러면 자기가 했던 작업들을 다 취소하고 새로 시작한다.
락 Lock은 기본적으로 비관적으로 남이 반드시 내 자원을 침범할 것이라 보고 미리 자물쇠를 걸어두는데 TM(Transactional Memory)은 낙관적으로 내 자원이 남에게 침범받지 않았을 거라고 가정하고 일단 해보는 것이다.
첨부한 프리젠테이션자료에 나오는 그래프처럼 어떤 상황에서는 일반적인 Lock이 프로세서가 늘어나면 각 프로세서에서 소모하는 시간이 기하급수적으로 늘어나는데 비해 TM은 상당히 괜찮다.
Review한 이 논문은 이 TM을 임베디드 환경에 맞춰서 간단한 TM을 가진 프로세서를 설계해 시뮬레이션해보고 어땠는지 보는 것이다. 결론은 "성능은 좋아진다. 그러나 Critical Section(프로그램에서 공유자원 사용하는 부분)에서 하는 일이 적을 경우 오히려 TM 기능을 구현하기 위한 하드웨어의 전력 소모때문에 전력은 일에 따라 TM쪽이 더 많이 소모되기도 한다. 그래서 TM을 임베디드에 적용하려고 해도 너무 간단하게는 말고 좀더 설계에 신경써야 된다." 이다. TM 자체를 처음 접하는 거라 공부삼아 리뷰했다. Cite된 논문들 읽는 것 벅찼다. 처음 보는 게 너무 많아서.. 결국 교수님께 모르는 부분 집혀서 곤란도 당했다.
I was senseless and ignorant; I was a brute beast before you.
Yet I am always with you; you hold me by my right hand.
You guide me with your counsel, and afterward you will take me into glory.
Whom have I in heaven but you?
I only have you in my life
by Daniel
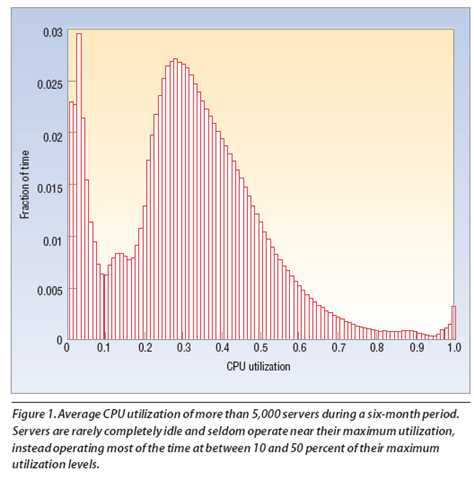
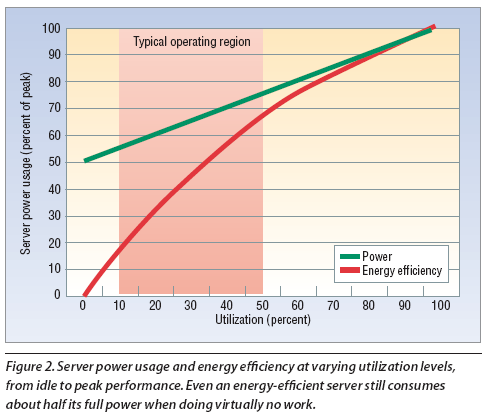

 Presentation-A Hardware_Software Framework for supporting Tran..
Presentation-A Hardware_Software Framework for supporting Tran..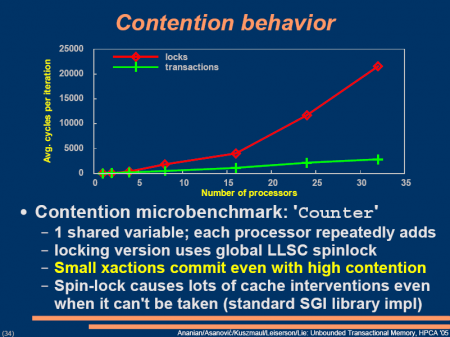
 I was senseless and ignorant; I was a brute beast before you.
Yet I am always with you; you hold me by my right hand.
You guide me with your counsel, and afterward you will take me into glory.
Whom have I in heaven but you?
I only have you in my life
I was senseless and ignorant; I was a brute beast before you.
Yet I am always with you; you hold me by my right hand.
You guide me with your counsel, and afterward you will take me into glory.
Whom have I in heaven but you?
I only have you in my life