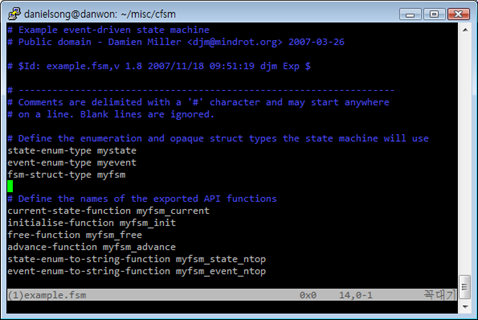
state T1 initial-state on-event T1_DONE -> T2 state T2 on-event T2_DONE -> T3 state T3 on-event T3_DONE1 -> T2 on-event T3_DONE2 -> T4 state T4
이런 간단한 스펙을 바꾸면,
...생략 switch(old_state) { case T1: switch (ev) { case T1_DONE: new_state = T2; break; default: goto bad_event; } break; case T2: switch (ev) { case T2_DONE: new_state = T3; break; default: goto bad_event; } break; case T3: switch (ev) { case T3_DONE1: ...후략
이런 코드가 생기고,
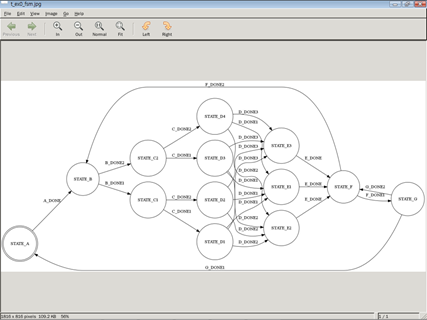
이런 그림으로 나타낼 수 있게 그래프 파일도 생성 됩니다.
Usage: cfsm [-h] [-HCD] [-o output-file] fsm-file Command line options: -h Display this help -d Generate C header file in addition to source file -D Only generate C header file (and not a source file) -g Generate Graphviz dot file instead of C source/header -m template_file "Manual" output mode using user-supplied template -o output_file Specify output file (default: fsm.[c|h|dot]) -t template_dir Specify path to C and Graphviz templates
창 크기 변경 엄청 느림, CSS 페이지 많이 느림, 그림 뜨는 시간 느림. 탭 지원 안됨.
프레임 지원, 또는 파서 지원이 약한 듯.
HTML parser error : Tag o:p invalid style='font-size:9.0pt;font-family:Verdana'><o:p></o:p></span></b></p> ^ namespace warning : Namespace prefix o is not defined style='font-size:9.0pt;font-family:Verdana'><o:p></o:p></span></b></p>
이런 에러가 좍 뜸.
midbrowser
모질라 게코 기반 임베디드용 브라우저라는데 실행시 에러남
가장 무거운 소스(45메가)
amaya
웹브라우저+HTML 에디터 W3C에서 제공하는 테스트베드 - 프레임지원 미비? 브라우저로 쓸 것은 아닌 것 같음
links gui
데비안 패키지 이름은 links2
links -g 로 실행하면 x화면, svga화면에서 실행할 수 있음.
아주 가벼움. 빠른 속도 그러나 한글 지원 못봤음. 역시 그림 이외엔 다른 지원 없을 듯. CSS 지원 완벽하지 않음.
이제껏 모르고 있었는데요
인텔 아톰 프로세서라는 게 출시 됐는데 TDP(파워)가 0.6~2.5와트 소모된다고 하고,
클럭은 1.8GHz까지 가능하다고 합니다. EM64T도 호환되고 HT도 지원하고요
VIA C3가 아니라 ARM에의 대항마인 것 같은데요
ISSCC2008에 소개되기도 했다고 하긴 하던데
The 2 GHz variant of the Silverthorne processor will operate at 1 volt and it will have performance equivalent to a first generation "Banias" Pentium M notebook processors circa 2003. Rattner confirmed this was for single-threaded performance on a broad range of applications. This would seem to imply that with multithreaded applications, the performance would be even higher than Banias which lacks Hyper-Threading.
Dual-Core Execution(DCE)이란 single thread 프로그램을 코어 두개로 실행해서 빠르게 하겠다는 것인데, 이번 논문은 여기에 중복되는 계산을 좀 줄여서 파워와 안정성을 개선하겠다는 것인 듯.
Compared to the original DCE, the optimized DCE has similar speedups (34 percent on average) over single-core processors while reducing the energy overhead from 93 percent to 31 percent.
역시 에너지는 싱글 코어 때보다 더 소모되긴 하는데, 속도 30% 증가에 에너지 30% 더 소모. linear하군요. 그게 진짜인지는 논문을 읽어봐야 할 듯.
Posted at 2008/05/16 18:44 //
in Research //
by Daniel
공학에서 최적화 문제는 현상을 representation 잘하는 수식을 찾아내되 풀수 있을 만큼 쉬운 수준의 식으로 찾아야 이후에 수식을 통해 최적을 찾을 수 있고 그렇지 않다면 heuristic으로밖에 갈 수 없다(NP문제가 됨). - 연세대 모정훈 교수 http://www.stanford.edu/class/ee364a/index.html
I was senseless and ignorant; I was a brute beast before you.
Yet I am always with you; you hold me by my right hand.
You guide me with your counsel, and afterward you will take me into glory.
Whom have I in heaven but you?
I only have you in my life
by Daniel





 I was senseless and ignorant; I was a brute beast before you.
Yet I am always with you; you hold me by my right hand.
You guide me with your counsel, and afterward you will take me into glory.
Whom have I in heaven but you?
I only have you in my life
I was senseless and ignorant; I was a brute beast before you.
Yet I am always with you; you hold me by my right hand.
You guide me with your counsel, and afterward you will take me into glory.
Whom have I in heaven but you?
I only have you in my life