리눅스의 유틸리티 wget은 http나 https, ftp로 파일을 다운로드 받을 때 커맨드라인에서 쉽게 받을 수 있는 프로그램입니다. 웹페이지가 있고 그 페이지에 여러 페이지나 자료의 링크가 있는데 이걸 다 받고 싶은 경우 wget 의 옵션을 사용하면 됩니다. (예를 들어 강의 페이지의 자료들을 한꺼번에 받고 싶을 때 말이죠)
일단 해당 페이지를 받습니다. $ wget URL
예를 들어 $ wget html://rommance.net/misc_path/a.html
그 다음 이 웹 페이지에서 나온 링크들을 전부 받습니다. 이제 사용하는 옵션은 -i : 뒤에 나오는 파일 안에 있는 URL을 다 다운로드 합니다. -F : 파일을 html로 인식한다. -B : Base URL(상대경로의 링크일 때 기본 베이스 주소) 이 세가지를 쓰면 됩니다.
멀티코어로 가는 대세 - 더이상 클럭을 올려서는 힘들고 여러개 코어로 나눠 일하는 concurrency 를 공략하는게 대세다 참고로 2003년 이후로는 거의 클럭이 올라가지 않고 있다. 클럭을 올려 속도를 빨리 하는 대신에 여러 코어에서 나눠 돌려서 전체적인 처리작업량을 늘리는 방법을 쓴다. 이렇게 하면 에너지(열)은 클럭주파수의 제곱에 비례하므로 낮은 클럭의 칩을 여러개 써서 높은 클럭 칩 하나로 일하는 것과 같은 성능을 낸다면 대체로 에너지를 더 적게 소모하고 열이 더 적게 나게 된다. 그러나 여러 코어에서 돌리려하면 일을 나누는 것, 그리고 나눠서 잘 돌아가게 관리해주는 게 필요하다.
예를 들어서 피자 집에서 배달을 시키는데 원래 한명이 배달하다가 손님이 많아져서 두명으로 늘렸다고 치자. 아무리 둘로 늘려도 효울이 두배로 늘려면 당연히 피자가 나오는 속도가 두배여야 한다. 그리고 혹, 오토바이나 피자 배달을 준비하기 위한 데크등이 공용된다면 공용되는 자원을 누가 먼저 사용하는지 규칙이 있어야 하고 한번에 한사람만 쓰도록 관리해줘야 한다.
원래 기존에 컴퓨터과학에서 많이 쓰던게 락(잠금)기법인데 잠가버려서 한번에 하나만 쓰게 보장된다. 그러나 혹시 락을 건 상태로 프로세스가 죽거나 잠들어버리면 다른 기다리는 프로세스들은 하염없이 기다리게 된다. 기타 여러 문제가 있는데 이걸 해결해보고자 transactional memory가 나왔었다. 최근에 멀티코어가 많이 나오면서 다시 재조명 받게 된 주제인데
컨셉은 일단 해본다. 그리고 잘 안되면 기다렸다 다시 한다. 이다.
그러니까 공유자원 A가 있다면 모든 각각의 프로세스에서 기본적으로 다른프로세스가 내가 자료 A를 처리하는 동안에 A를 바꾸지 않았다는 가정하에 일단 계산을 해본다. 프로세스1이 그랬다고 치고 그리고 A값을 아마 업데이트 할텐데 그 전에 혹시 다른 프로세스가 A를 바꿨다면 이 프로세스1은 바꿨다는 것을 인식하게 된다.(인식하는 방법은 이 논문에 나온 방법은 하드웨어적으로 Cache Coherency를 이용한다.) 이때 Abort가 발생한다. 그러면 자기가 했던 작업들을 다 취소하고 새로 시작한다.
락 Lock은 기본적으로 비관적으로 남이 반드시 내 자원을 침범할 것이라 보고 미리 자물쇠를 걸어두는데 TM(Transactional Memory)은 낙관적으로 내 자원이 남에게 침범받지 않았을 거라고 가정하고 일단 해보는 것이다.
첨부한 프리젠테이션자료에 나오는 그래프처럼 어떤 상황에서는 일반적인 Lock이 프로세서가 늘어나면 각 프로세서에서 소모하는 시간이 기하급수적으로 늘어나는데 비해 TM은 상당히 괜찮다.
Review한 이 논문은 이 TM을 임베디드 환경에 맞춰서 간단한 TM을 가진 프로세서를 설계해 시뮬레이션해보고 어땠는지 보는 것이다. 결론은 "성능은 좋아진다. 그러나 Critical Section(프로그램에서 공유자원 사용하는 부분)에서 하는 일이 적을 경우 오히려 TM 기능을 구현하기 위한 하드웨어의 전력 소모때문에 전력은 일에 따라 TM쪽이 더 많이 소모되기도 한다. 그래서 TM을 임베디드에 적용하려고 해도 너무 간단하게는 말고 좀더 설계에 신경써야 된다." 이다. TM 자체를 처음 접하는 거라 공부삼아 리뷰했다. Cite된 논문들 읽는 것 벅찼다. 처음 보는 게 너무 많아서.. 결국 교수님께 모르는 부분 집혀서 곤란도 당했다.
Posted at 2008/02/28 11:02 //
in Programming //
by Daniel
Recursive version 64비트 지원하도록 바꿈.
#include <stdio.h> /* Required to use printf() */
typedef unsigned long long u64;
typedef long long i64;
//#define i64 (long long)
/* Function l(n1,n2,n) calculates f(n) using parameters n1 and n2
* * to store the two previously calculated Fibonacci numbers */
long long l(long long n1,long long n2,long long n) {
//printf("l(%lld,%lld,%lld)=%lld\n", n1, n2, n, (n<2 ? n1 : l(n1+n2, n1, n-1)));
return n<2 ? n1 : l(n1+n2, n1, n-1);
}
/* Function f(n) returns the n'th Fibonacci number
* * It uses ALGORITHM 2B: SIMPLE RECURSION
* */
long long f(long long n) {
return l(1,1,n);
}
/* Function f_print(n) prints the n'th Fibonacci number */
void f_print(long long n) {
printf("%lldth Fibonacci number is %lld\n",n,f(n));
}
/* Function main() is the program entry point in C */
int main(int argc, char* argv[])
{
long long n=45;
if (argc > 1)
n = (long long) atoi( argv[1]);
f_print(n);
return 0;
}
Non recursive version
#include <stdio.h>
unsigned int f(int n) {
int i;
unsigned int n1=1,n2=1;
for(i=1; i<=n; i++) {
n1+=n2;
n1^=n2^=n1^=n2; /* C trick to swap n1 and n2 */
}
return n1;
}
/* Function f_print(n) prints the n'th Fibonacci number */
void f_print(int n) {
printf("%dth Fibonacci number is %lu\n",n,f(n));
}
int main(int argc, char* argv[])
{
int n=45;
if (argc > 1)
n = atoi( argv[1]);
f_print(n);
return 0;
}
Posted at 2008/02/26 21:15 //
in Research //
by Daniel
http://asmlove.co.kr/zBdC7/download.php?id=280 (원문이 자세함.) 1. Fully Associative Cache Schematics Fully Associative 캐시는 Cache Set으로 캐시를 나누지 않고 태그 정보로만 데이터를 찾는다. 단순하게 복잡도를 계산해보면 최악의 경우 2^T 번의 태그 비교가 필요해지므로 O(2^T)의 계산 복잡도를 가진다. T비트의 비교기는 동작 속도가 매우 빠르지만 캐시 메모리가 커질수록 태그 값을 찾는데 긴 시간이 필요하다는 단점이 있다. 하지만 데이터의 주소를 그대로 캐시 메모리에 저장하므로 유연성이 높다는 장점도 있다.
2. Direct-Mapped Cache Schematics Fully-Associative 방식을 보완한 것이 Direct-Mapped 방식이다. 메모리 주소를 태그, 셋, 오프셋으로 나누고, 캐시 메모리도 셋 단위로 나눠서 관리한다. 셋 번호에 따라 어느 캐시 라인에 데이터가 있는지 먼저 찾고, 그 안에서 태그 값을 비교해서 원하는 캐시 데이터가 맞는지 확인하는 방식이다. 캐시 라인의 번호가 Cache Set의 번호가 된다. 따라서 셋 번호를 검색하는 시간이 줄어들고 태그 번호만 비교하면 된다. Fully Associative 방식에 비해 동작 속도가 매우 빨라진다. 제작 비용이 싸지는 장점이 있지만 동일한 셋 번호를 가지는 메모리 주소를 함께 저장할 수 없다는 단점이 있다. 따라서 연속된 메모리 데이터를 캐시에 저장할 수 없게 되고, 캐시의 성능이 떨어지게 된다. 예를 들어 0x16339C와 0x16338C는 같은 셋 번호를 가지므로 같은 캐시 라인에 들어가게 된다. 따라서 캐시에는 둘 중 하나의 데이터만이 저장되고 두 데이터가 동시에 저장될 수 없다. 가까운 메모리가 함께 사용된다는 Locality를 생각해보면 매우 성능상에 문제를 가져올 수 있다.
3. Set-Associative Cache Schematics Set-Associative 방식은 위의 두가지 방식의 장점들을 합쳐서 만든 방법이다. 캐시를 태그로만 나누는 것이 아니라 같은 셋 값으로도 나누어서 태그 값이 같지만 셋 값이 다른 데이터들도 캐시에 저장될 수 있도록 한다. n-Way Set-Associative 라는 말은 그림과 같이 태그가 같은 데이터 라인이 n개까지 있을 수 있다는 말이다. 즉, 태그가 다르고 셋 값이 같은 데이터 라인이 몇 개가 캐시에 있을 수 있는지를 나타내는 말이다. 여기에서 n 값이 너무 높아지면 Fully Associative 방식의 단점이 나타나고, n 값이 너무 작아지면 Direct Mapped 방식의 문제가 나타나므로 Trade Off에 대한 고려가 필요해진다.
I was senseless and ignorant; I was a brute beast before you.
Yet I am always with you; you hold me by my right hand.
You guide me with your counsel, and afterward you will take me into glory.
Whom have I in heaven but you?
I only have you in my life
by Daniel
 Presentation-A Hardware_Software Framework for supporting Tran..
Presentation-A Hardware_Software Framework for supporting Tran..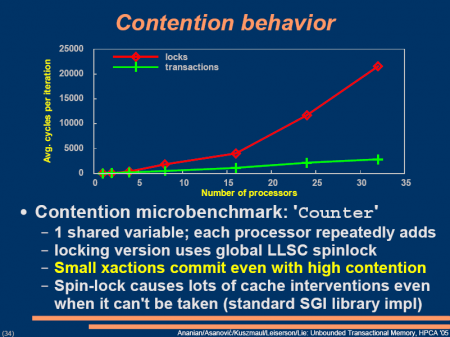

 I was senseless and ignorant; I was a brute beast before you.
Yet I am always with you; you hold me by my right hand.
You guide me with your counsel, and afterward you will take me into glory.
Whom have I in heaven but you?
I only have you in my life
I was senseless and ignorant; I was a brute beast before you.
Yet I am always with you; you hold me by my right hand.
You guide me with your counsel, and afterward you will take me into glory.
Whom have I in heaven but you?
I only have you in my life